
In deep learning, activation functions help neural networks learn complex patterns. Specifically, they decide if a neuron activates, introducing non-linearity. ReLU is a common choice. However, advanced models, especially in natural language processing, often need better alternatives. Consequently, the GELU (Gaussian Error Linear Unit) activation function has emerged as a powerful and widely used component. Indeed, it’s widely used in transformer architectures like BERT and GPT. This post, therefore, explains GELU’s mathematical basis, function, advantages, and its role in modern deep learning.
How GELU Activation Works: GELU Activation Explained
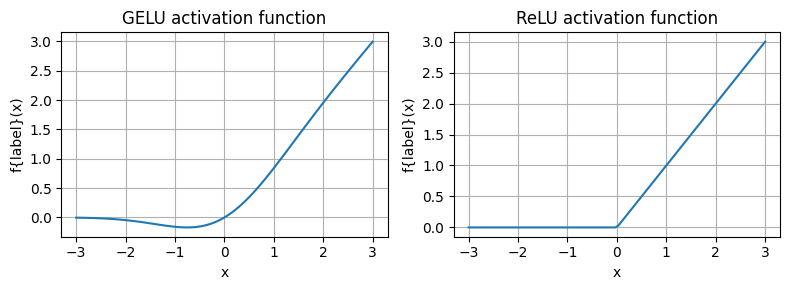
GELU is a smooth, non-monotonic alternative to ReLU. In contrast, ReLU outputs the input if positive, else zero. GELU, however, uses a probabilistic approach. It weights input x by its probability under a Gaussian distribution. This means, consequently, that GELU’s output is a scaled version of the input. The scaling factor, moreover, comes from the standard normal distribution’s cumulative distribution function (CDF).
The Mathematical Formulation
The mathematical formula for GELU is:
GELU(x) = x * Φ(x)
Here, Φ(x) is the standard normal distribution’s cumulative distribution function (CDF). We can express Φ(x) using the error function erf(x):
Φ(x) = 0.5 * (1 + erf(x / √2))
Substituting this into the GELU formula, we thus get:
GELU(x) = 0.5 * x * (1 + erf(x / √2))
This formula, therefore, shows GELU’s key difference from other activation functions. The erf(x) component, furthermore, creates a smooth, non-linear transformation for nuanced activation patterns. The x term, moreover, acts as a gate, scaling the output based on the input’s value and its activation probability. This probabilistic gating mechanism, consequently, makes GELU effective in deep learning models.
Intuitive Understanding
To understand GELU intuitively, consider a neuron receiving input x. Instead of simply activating based on a threshold (like ReLU), GELU, instead, considers x‘s ‘likelihood’ of importance. For instance, if x is very large and positive, Φ(x) approaches 1, and GELU(x) is approximately x. Conversely, if x is very small and negative, Φ(x) approaches 0, and GELU(x) is approximately 0. However, for x values around zero, Φ(x) is between 0 and 1. This, consequently, leads to a smooth, non-linear scaling of x. This smoothness and non-monotonicity, furthermore, improve gradient flow through the network, thereby aiding deeper model training.
This is how gelu activation explained in a way that highlights its unique properties and advantages over traditional activation functions. The smooth transition and probabilistic gating mechanism contribute to its superior performance in various deep learning tasks.
Key Components and Benefits of GELU Activation
The effectiveness of GELU stems from several key components and the benefits they bring to neural network training and performance:
1. Smoothness and Differentiability
Unlike ReLU, GELU is smooth across its entire domain. ReLU, in contrast, has a sharp, non-differentiable point at x=0. GELU’s smoothness is vital for gradient-based optimization. A smooth activation function, moreover, ensures well-behaved gradients, preventing abrupt changes. This, in turn, leads to more stable and efficient training, especially in deep networks. GELU’s continuous differentiability, furthermore, helps avoid issues like ‘dying ReLUs,’ where neurons become inactive and stop learning.
2. Non-monotonicity
GELU is a non-monotonic function. This means its output does not strictly increase or decrease with its input. This property, therefore, allows GELU to capture more complex data relationships. ReLU is monotonic. However, GELU’s non-monotonicity models intricate patterns. It, consequently, provides richer representational capacity for the neural network. This, furthermore, benefits tasks where input-output relationships are highly non-linear and complex.
3. Probabilistic Gating
GELU uses a probabilistic gating mechanism. Specifically, it multiplies input x by the standard normal distribution CDF Φ(x). This, therefore, effectively gates the input based on its statistical significance. Important inputs (those with higher probability under the Gaussian distribution) pass through with less attenuation. Conversely, less significant inputs are attenuated more. This adaptive gating, consequently, allows the network to selectively activate neurons based on input relevance, leading to robust feature learning.
4. Improved Performance in Transformer Models
GELU offers significant advantages in transformer architectures. Indeed, models like BERT, GPT-2, and GPT-3, which revolutionized natural language processing, use GELU extensively. GELU’s smooth and non-monotonic nature, combined with probabilistic gating, improves gradient flow and training stability. This, in turn, leads to superior performance in language understanding, generation, and translation. Furthermore, it helps mitigate the vanishing gradient problem in very deep transformer layers.
5. Compatibility with Normalization Layers
GELU works well with normalization techniques like Layer Normalization, which are common in transformer models. Its smooth nature, moreover, helps maintain stable activations and gradients with these layers. This, furthermore, improves the overall stability and performance of deep neural networks.
In summary, GELU’s unique combination of smoothness, non-monotonicity, and probabilistic gating provides a powerful activation mechanism that has significantly contributed to the advancements in deep learning, particularly in the domain of large-scale language models. Its ability to facilitate better gradient flow and capture complex data relationships makes it a preferred choice for many modern neural network architectures.
Real-World Applications of GELU
GELU offers significant performance improvements in real-world deep learning applications. This is especially true where complex dependencies and large datasets are involved. Consequently, its adoption in cutting-edge models highlights its practical utility.
1. Natural Language Processing (NLP)
GELU has significantly impacted Natural Language Processing (NLP). For example, transformer-based models like Google’s BERT [1] and OpenAI’s GPT series [2] widely use GELU. Furthermore, many other large language models (LLMs) also rely on it. In these models, GELU helps:
- Capture Contextual Nuances: Its non-monotonicity and probabilistic gating, for instance, help transformers understand subtle contextual relationships. This is crucial for tasks like sentiment analysis, named entity recognition, and question answering.
- Improve Gradient Flow in Deep Architectures: Transformer models are very deep. Consequently, GELU’s smoothness maintains stable gradients across many layers. This, therefore, prevents vanishing or exploding gradients during training.
- Enhance Language Generation: For generative models like GPT, GELU helps produce coherent, contextually relevant, and human-like text. In essence, it enables the model to learn intricate language patterns.
2. Computer Vision
GELU initially gained prominence in NLP. However, it now appears in computer vision tasks, especially with vision transformers and hybrid architectures. In these applications, GELU can:
- Process Image Patches Effectively: Images are broken into patches and processed by transformer-like blocks. GELU, therefore, helps learn rich representations from these visual tokens. This, consequently, improves performance in image classification, object detection, and segmentation.
- Improve Feature Extraction: In CNNs or hybrid models, replacing traditional activations with GELU can, furthermore, lead to more robust and discriminative feature learning, particularly in deeper layers.
3. Speech Recognition and Audio Processing
Transformer architectures increasingly apply to speech and audio processing. GELU handles sequential data and complex patterns well, making it suitable for:
- Acoustic Modeling: In end-to-end speech recognition, for example, GELU models intricate relationships between acoustic features and phonemes/words.
- Audio Synthesis: For tasks like text-to-speech or music generation, GELU, moreover, improves audio quality and naturalness. It, therefore, enables models to learn sophisticated sound representations.
4. Reinforcement Learning
In advanced reinforcement learning, GELU can, for instance, serve as an activation function. This is especially true for setups using deep neural networks for policy or value approximation. Its smooth nature, moreover, contributes to more stable learning dynamics in complex environments.
The widespread adoption of GELU across these diverse domains is a testament to its effectiveness and versatility. Its ability to facilitate better learning in deep, complex neural networks has made it an indispensable tool for researchers and practitioners pushing the boundaries of AI.
Challenges and Limitations
While GELU offers significant advantages, it is important to acknowledge its challenges and limitations. After all, no activation function is a silver bullet for all deep learning problems.
1. Computational Cost
GELU has a primary limitation: its computational complexity. Specifically, calculating the cumulative distribution function (CDF) of the standard normal distribution, which involves the error function (erf), is more intensive than a simple max(0, x) operation. While deep learning frameworks are optimized, this overhead can, nevertheless, affect fast inference or training on resource-constrained devices. Therefore, approximations like QuickGELU are sometimes used. They, consequently, reduce computational cost while retaining most benefits.
2. Not Always Superior to Simpler Activations
GELU performs well in many advanced architectures, especially transformers. However, it is not always superior to other activation functions. For simpler neural networks or specific tasks, for instance, ReLU or its variants (Leaky ReLU, ELU) might perform comparably or better. They also, furthermore, offer lower computational cost. The optimal activation function, therefore, depends on the network architecture, dataset, and problem. Extensive experimentation is, consequently, usually required.
3. Understanding the Probabilistic Gating
The probabilistic gating mechanism is a strength. However, understanding its implications and interactions with network layers and normalization techniques can be complex. Indeed, it is more complex than understanding ReLU’s straightforward thresholding. This might, therefore, create a steeper learning curve for newcomers. Still, deep learning libraries often abstract its practical application.
4. Potential for Vanishing Gradients in Extreme Cases
GELU aims to mitigate vanishing gradients through its smoothness. However, in extremely deep networks or with certain initializations, gradients can still become very small. This is especially true for very large negative inputs where Φ(x) approaches zero. While less prone to this than sigmoid or tanh, it is, nevertheless, not entirely immune. Therefore, careful network design and regularization remain necessary.
Despite these limitations, the benefits of GELU, particularly its ability to enhance the performance of complex models like transformers, often outweigh its drawbacks in many cutting-edge applications. Researchers continue to explore new variants and approximations to further optimize its efficiency and applicability across an even wider range of deep learning tasks.
Conclusion
The GELU (Gaussian Error Linear Unit) activation function represents a significant advancement in the field of deep learning, particularly in the context of modern neural network architectures like transformers. Its unique properties—smoothness, non-monotonicity, and probabilistic gating—address some of the limitations of traditional activation functions, leading to more stable training and enhanced performance in complex tasks.
From revolutionizing Natural Language Processing with models like BERT and GPT to finding applications in computer vision and speech recognition, GELU has proven its efficacy in enabling neural networks to learn richer, more nuanced representations of data. While it introduces a slightly higher computational cost compared to simpler alternatives, the performance gains it offers in state-of-the-art models often justify this trade-off.
As deep learning continues to evolve, the quest for optimal activation functions remains a critical area of research. GELU stands as a testament to the power of innovative mathematical formulations in pushing the boundaries of artificial intelligence. Understanding and leveraging activation functions like GELU is essential for anyone looking to build and deploy high-performing deep learning systems in today’s rapidly advancing technological landscape.
References
[1] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171-4186.